How does AI work?

Typical pipeline
Problem Formulation is an essential step to formulate a problem in a “machine learning language”
What is the input? What is the output? What is the task?
Input: images of cats and dogs;
Output: whether the images are cats or dogs;
Task: Predictive or Classification task.
What is the input representation? What is the output representation? What is the objective function?
Input representation: Images.
Output representation: Scalars.
Objective function: measurement between the predicted labels and ground truth labels (cross-entropy loss is very common for classification tasks)
Data Preparation/Processing is conducted after problem formulation. The data could be accumulated, or specifically curated for the formulated problem. It is utilized to collect and manipulate the data to produce meaningful information under the formulation of the problem.
Data Representation is another important step to represent data in a machine-readable (or numeric) format. The type of representation is also critical to model choice and which type of specific information it aims to capture.
Model Choice is another important step in the pipeline which determines the key model used to learn to fulfill the task. It mainly includes traditional machine learning models and deep learning models. In addition to the model choice itself, for a model to learn from data efficiently, we often need to design a measurement or objective function such that the model can be aware of how good or bad it is performing, then an optimizer is needed to adjust the model accordingly.
Traditional ML Models (Modeling data w/ limited structured inductive bias (i.e. data is not always assumed to be in certain structure like graph))
Random Forests, Support Vector Machine, Gradient Boosting, etc.
Deep Learning Models (Modeling data w/ structured inductive bias)
Multi-layer Perceptron (MLP) models all types of data (without structure inductive bias)
Convolutional Neural Network (CNN) models grid data
Recurrent Neural Network (RNN) models sequence data
Graph Neural Network (GNN) models graph data
Transformer models sequence data originally, but later adapted to model all types of data
Objective/Loss Function
Mean-squared error loss for regression task
Cross-entropy loss for classification task
More to read: Common Loss functions in machine learning [5]
Optimizer is the algorithm used to minimize the objective/loss function and update the parameters of the machine learning model. More to read [6]
Common optimizers include SGD, Adam, RMSProp, etc.
Evaluation/Result Analysis is conducted to evaluate the performance of the model and provide feedback to improve the whole pipeline.
Training/Validation/Testing Set Evaluation (Common procedure: tuning parameters on the training set, select the parameters that have the best performance on the validation set and report the result on the testing set to mimic the real-world scenario when unseen/new data come as the testing set)
Evaluation Metrics measure the performance of the model.
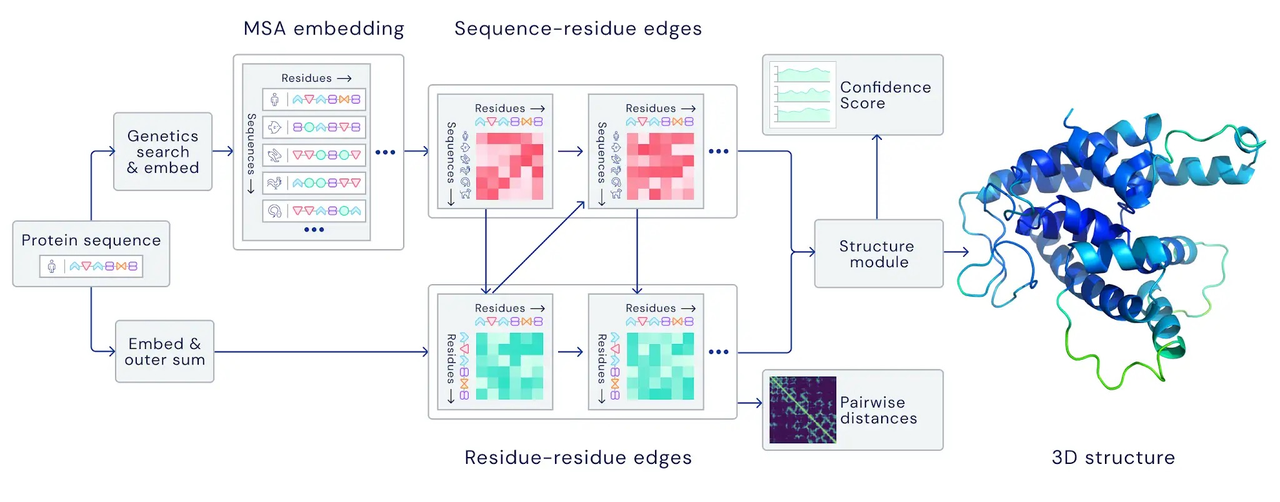
Real-world Example (Protein Structure Prediction - Alphafold2)
Problem Formulation
Input: protein sequence (a sequence of N amino acids)
Output: protein structure (coordinates of amino acids in 3D space -> (N \times 3))
Task: predictive or regression task
Data Preparation
Accumulated protein structures from Protein Data Bank (PDB) (sequence, structure pairs)
Searching Multiple Sequence Alignment (MSA) for each protein sequence (demonstrated to help with learning coevolutionary information)
Accumulated protein templates (existing templates for some proteins)
Model Choice - Deep Learning Models
Transformers in modeling MSA embeddings and producing pairwise and single-sequence features
Transformers in modeling pairwise and single-sequence features and output structures
Objective Function
Cross-entropy loss, mean-squared-error loss, etc.
Optimizer - Adam Optimizer
Evaluation/Result Analysis
TMScore, lDDT (measurement between two structures)
plDDT, pTMScore (predicted lDDT/TMScore for uncertainty estimation)